Breathing new life into old data: how to retro-digitize a dictionary
I have recently worked on a project where we retro-digitized two Irish dictionaries and published them on the web, so I thought it would be a good idea to summarize my experience here. Hopefully somebody somewhere will find it useful.
In the slang of people who care about such things, retro-digitization is the process of taking a work that had previously been published on paper (often a long time ago, way before computers made their way into publishing) and converting it into a digital, computer-readable format. A bit like retro-fitting a house or pimping up an old car. This involves not only scanning and OCRing the pages, but also structuring and indexing the content so it can be searched and interrogated in ways that would have been impossible on paper. This is the bit that matters most if what you are retro-digitizing is a dictionary.
The dictionaries we retro-digitized are Foclóir Gaeilge-Béarla [Irish-English Dictionary] from 1977 (editor Niall Ó Dónaill), and English-Irish Dictionary from 1959 (editor Tomás de Bhaldraithe). Both are sizeable volumes which, despite their age, enjoy the respect, even adoration, of Irish speakers everywhere, are still widely used and widely available in bookshops. People have been saying for ages how nice it would be if we had electronic versions of these. And now we do, available freely to everybody on a website. Here’s how we got there.
Step 1: Getting your hands on the text
We were lucky to already have access to machine-readable versions of the two dictionaries, so no scanning or OCRing was necessary. In the case of English-Irish Dictionary (EID from now on), the text had already been scanned, OCRed, proof-read and even marked-up into a fairly detailed XML structure before it landed on my desk. The trouble was that much of that structure had been lost again in the process of proof-reading the text: people were using Microsoft Word which only preserved some of the structure, basically just bold and italics and not much more. Still, better than starting from paper.
Foclóir Gaeilge-Béarla (FGB from now on) was a different matter. I had access to a typesetting file from which the dictionary had originally been printed. I have no idea where that file came from but I assume it was the output of some early DTP software. It contained the entire text of the dictionary interlaced with formatting mark-up which was quite unlike anything I had seen before (see pic 1). But luckily it was not hard to make sense of and, again, this was a lot better than starting from paper. In fact, it was better than starting from OCRed text because you could take for granted that there were no spelling errors – none that wouldn’t be in the printed version too, at least.
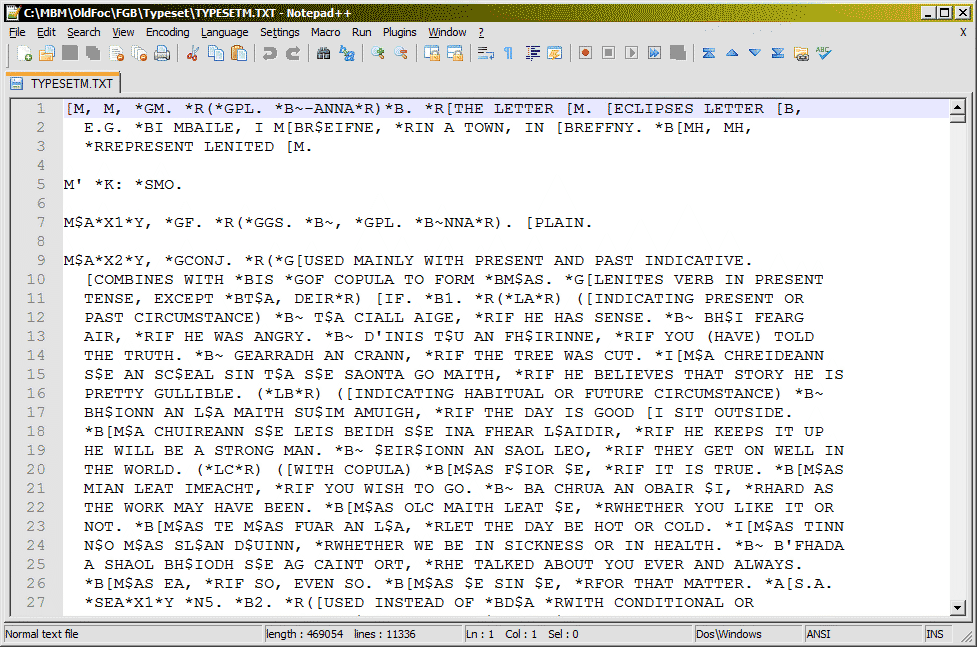
Step 2: Structuring the entries
Modern born-digital dictionaries often have a complex and explicit structure, usually encoded in XML, where each entry is subdivided into senses, usage examples, various kinds of sub-entries, grammatical labels and so on. You can forget about all that when dealing with a paper-born dictionary though: the entries are just paragraphs of text, sometimes with surface formatting like bold and italics, but very little explicit structure beyond that. As a retro-digitizer, you need to be able to infer just enough structure from this to produce something useful, something that beats paper.
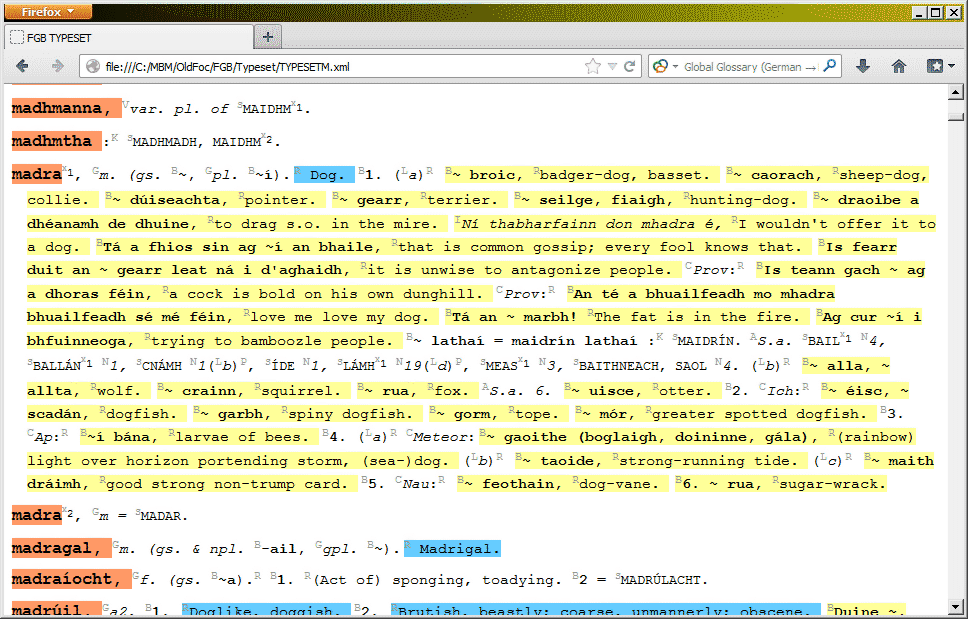
In FGB, I was able to use the formatting codes from the typesetting file to infer where one sense ended and another began, where one usage example ended and another began, what was a grammatical label and what was a translation, and so on. Pic 2 shows an example entry in its original formatting (you can see it’s basically just text with bold and italics), with the inferred structure indicated by colour-coding and superscripts. The accuracy was so high that we decided not to do any manual proof-reading, at least not for now.
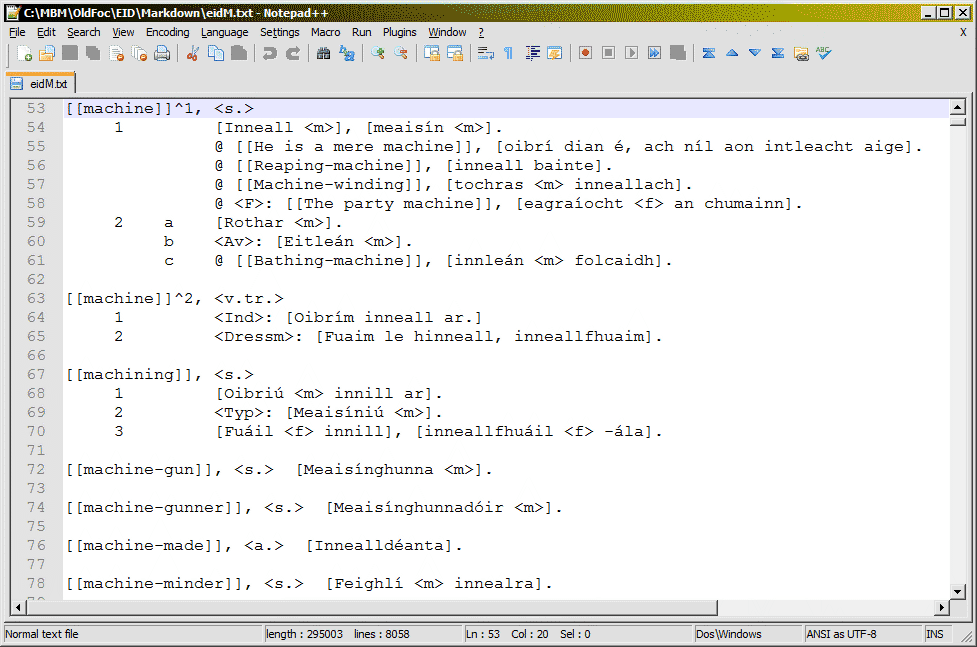
EID was a tougher beast to tame. Even though I was able to infer a lot of structure too, the accuracy was far from acceptable and we decided we needed to do a fair bit of manual proof-reading and correction. The question was, how? The lexicographers on our team, highly able as they are, couldn’t be expected to edit raw XML. There was no time to look for a suitable editorial GUI as the deadline was looming large. So, in a sudden fit of inspiration, I devised a plain-text notation that was explicit enough structurally while still being readable by humans. Pic 3 shows an example. There are various notational conventions: square brackets enclose text in the target language (Irish), double square brackets in the source language (English), an ampersand @ says the rest of the line is a usage example, and so on. I think I may have accidentally invented a markdown format for dictionaries. With a plain-text editor and a team of several people, we were able to proof-read the entire dictionary in a few weeks and bring the structural mark-up to an acceptable level of accuracy.
Our strategy in both dictionaries was to mark up the text without altering it. We wanted to keep the text exactly as it appeared in the printed version. The other option would be to reinterpret and restructure the entries to bring them closer to modern lexicographic standards, but we did not dare to do that.
Step 3: Wrapping it up in a pretty website
Now your job merges with that of somebody working on a born-digital dictionary: you have a bunch of XML files and you need to build a pretty user interface where people can search and browse. Because you are now on a computer and not on paper any more, you can do things that would have been impossible on paper. Our website has things like reverse search (a search from the target language to the source language) and searches that match things deep inside the entries rather than just the headwords. The two dictionaries are very rich in examples and contain literally hundreds of thousands of example sentences. So we have a feature that lists example sentences for a given word or combination of words, even if they are under a completely unrelated headword. All of these searches are morphology-aware and spell-checked of course, as one would expect of any online dictionary worth its name.
Our website was launched at the Oireachtas na Gaeilge festival this autumn (2013) and has been received with much enthusiasm – over 10,000 pageviews on the first day!
Summary
When retro-digitizing a dictionary, the most basic question is, should you do it at all? Old dictionaries are usually slightly out of date in the sense that they no longer fully describe the language as it is spoken nowadays. On the other hand, they contain a lot of potentially useful information which is still valid and which you can make available pretty quickly, probably a lot quicker than writing a new dictionary from scratch. Also, old dictionaries are often well-known “brands” and this will rub off onto your digital product, guaranteeing you a good reception from the public – provided you do a good job of the digitization.
Provided, yes. Digitizing old data can be a nightmare. The data had been written entirely by humans, so you must expect annoying little inconsistencies everywhere. There will be grammatical labels that nobody knows what they mean, there will be gaps in homonym numbering, there will be dead cross-references. All this will conspire to limit what you can do in terms of structure, mark-up and search. So it’s a game of finding a good balance between what’s desirable and what’s possible. I hope the balance we have found for FGB and EID is good.