What lexicographers need to know about DMLex
An unofficial introduction to the Data Model for Lexicography
Attention all lexicographers! There is a new show in town: the Data Model for Lexicography, or DMLex for short. DMLex is a newly proposed standard for structuring (human-oriented) dictionaries which my colleagues and myself have been developing for the last couple of years in LEXIDMA, a technical committee under OASIS, an organisation which oversees the production of open standards in the IT industry. Because – for my sins – I am LEXIDMA’s chair, I have taken it upon myself to write this article as an introduction to DMLex: to explain the reasoning behind why DMLex is the way it is, and to show how DMLex might be used to represent real-world dictionaries.
I am writing this at a time when DMLex has entered its second round of public reviews and we are looking for feedback. But I’m aware that asking people to read the entire DMLex specification is a big ask: it is a 197-page PDF! So I have distilled (what I think are) the most interesting points about DMLex into this article. Just bear in mind that what you’re reading here is my personal and unofficial interpretation. My colleagues in LEXIDMA might choose to emphasise slightly different points or to approach it from another angle. But I think I haven’t wandered too far away from our groups’s consensus in what I have written here.
Does the world need another lexicographic data standard?
Of course, DMLex isn’t the only standardised schema in existence for constraining the structure of dictionary entries. Others you may have heard of are TEI (including TEI-Lex0), LMF (recently updated) and Lemon (with its Lexicography Module). These standards definitely do exist – but nobody cares about them much. Most dictionary projects happily ignore all standards and design their own home-baked schemas. So what’s the point of bringing another one into the world?
Pretty much all existing standards (and pretty much all home-baked schemas I have seen) have one thing in common: they model dictionary entries as tree structures. A tree structure is what you have in XML: every XML document is basically an upside-down tree where elements branch into other elements which branch into even more elements. At first sight, this seems like a good fit for dictionary entries with their hierarchical arrangement of entries which contain senses which contain definitions and so on. But tree structures have disadvantages too. For example, they are really bad at representing cross-references between entries if you want to make sure that your cross-references always remain valid (= if you want to prevent “dangling” references to non-existent targets). Graph structures (such as relational databases and RDF graphs) are much better at doing this. Another limitation of tree structures is that they force lexicographers into having to make uncomfortable decisions about the placement of multi-word subentries: do you really have to decide whether black hole goes under black or hole? Can’t you have it both ways? Well, in tree-structured XML you can’t (at least not easily, not out-of-the-box). Graph structures are again much better at doing that kind of thing.
In LEXIDMA, we thought that it was time to propose a new approach to modelling dictionaries: one which would be a hybrid between tree structures for the basic entries-and-senses hierarchy, and graph structures for everything else. The point of DMLex is not to be yet another ivory-tower standard which real-world dictionaries would ignore. Instead, the point of DMLex is to propose a catalog of design patterns which you could take inspiration from if, for example, you’re building a dictionary writing system and if your ambition is to handle all these complex phenomena – cross-references, multi-word subentries and similar – in a slightly more intelligent way than before.
DMLex is a data model – but what’s a data model?
If you are a working lexicographer, you are probably familiar with dictionary entries being encoded in XML, and with the internal structure of these entries being constrained by an entry schema (such as a DTD). An entry schema is something which tells you (and your software) that, for example, an entry is supposed to contain exactly one headword followed by a list of one or more sense, that each sense is supposed to contain at most one definition, and so on.
Well, a data model is like such a schema, but more abstract. An XML schema is very closely coupled with the notation of XML. A data model, on the other hand, is not coupled with any specific notation or formalism. A data model is one level of abstraction above that: it is something than can be implemented in many notations and formalisms. DMLex is such a data model. It defines the structure of dictionaries (called ‘lexicographic resources’ in DMLex) in a way which can be“serialised” into many different formalisms. The DMLex standard comes with serialisations of itself into XML, into JSON, into a relational database, into an RDF graph (you know, Semantic Web stuff) and into one less well-know language called NVH.
In the rest of this article, I will walk you though how we, the authors of DMLex, have decided to represent in DMLex the various phenomena that come up when you’re planning the structure of a dictionary. In each subsection, I will only show you the abstract structure (using diagrams with boxes and lines between them). I will not be showing you serialisations into the different formalisms because then this article would be too long. But please always remember that what you’re looking at is at a higher level of abstraction than what you may have worked with before in lexicography. A real-world application would choose to implement DMLex as something more specific: a relational database, an RDF graph, a bunch of XML documents or JSON objects, or something else.
The basics: entries and senses
Let’s start our tour of DMLex with something most lexicographers will recognise as familiar. How does DMLex represent the basic skeleton of dictionary entries as things that are headed by headwords and then subdivided into senses? DMLex isn’t reinventing any wheels here and does the same thing all other data models do too: we model this as a tree structure. Figure 1a shows a simple dictionary entry and Figure 1b shows how the same entry would be modelled in DMLex.


We can use this diagram as an introduction to the meta-model behind DMLex. DMLex sees each dictionary as a collection of objects of certain types such as entry, sense, definition: DMLex defines which types exist. In my diagrams the type of each object is given in a shaded heading at the top (sometime at the bottom) of the box. The rest of the box contains the object's properties: DMLex defines which properties an object can have based in its type. A property has a name (such as headword, definition, listingOrder) and a value. In my diagrams the property's name comes before the colon and the value after it, such as headword: colour. The value of a property can be either something atomic, like a short string of text or a number, or a reference to another object. Notice how, in Figure 1 for example, there is an object of type entry which has three properties: headword, partOfSpeech and sense. The value of headword is atomic (a string of text) while the values of partOfSpeech and sense are references to other objects. In my xiagrams references are indicated as arrows which point to the object they refer to.
DMLex can be used for representing monolingual dictionaries like above, but it can also represent bilingual dictinaries like in Figures 1c and 1d. As if that weren’t enough, DMLex can also represent multilingual dictionaries: those are dictionaries which have one source language and multiple target languages.


What, only one headword per entry?
DMLex is very strict about allowing only one headword per entry. This may strike you as surprising. It is, after all, quite common in lexicography that an entry has not just a headword but also variant co-headwords, secondary headwords and so on. This happens when lexicographers are describing spelling variants (colour and color), gender-paired nouns (German Lehrer ‘male teacher’ and Lehrerin ‘female teacher’), aspect-paired verbs (Czech přistávat ‘to be landing’ and přistát ‘to have landed’) and so on. Does what I’m saying mean that these things cannot be represented in DMLex?
No, they can. The DMLex way to do it is to create a separate entry for each, and then to connect them with an object of type relation. Figure 2a shows an example of that: this is how you would represent in DMLex the fact that colour and color are spelling variants.

Notice how the entry for colour is labelled as ‘European spelling’ and the entry for color as ‘American spelling’. These labels can be defined for each dictionary separately, they are not prescribed by DMLex (the same goes for part-of-speech labels and other such things, by the way).
Notice also how the entry for colour contains a lot of information (a part-of-speech label and a sense) while the entry for color is sparse and skeletal: its purpose is only to serve as a member in the relation object. In DMLex it is perfectly OK to have entries with no senses for this purpose.
This is how the data is represented in DMLex internally, but it’s not necessarily what a human dictionary user would see on their screen (or on a printed page). The idea is that when your software (= your website or your app) is about to show one of these entries to a human user, it needs to follow through on all the relation objects and compose a “view” of the entry from them. Figure 2b shows a suggestion of what the entries for colour and color might look like when displayed on someone’s screen. If you’re using DMLex to store a dictionary in your software internally, then your software needs to be programmed to derive these human-friendly presentations from the data model.

This may seem more complicated than necessary at first. Why have we decided to do it this way instead of simply allowing entries to have multiple headwords? Our motivation for choosing the design pattern we have chosen is computational simplicity. Multi-headword entries cause all sorts of complications for automated processing, for example when sorting entries alphabetically or when matching dictionary entries to words in a text. These computational tasks become simpler if you’re able to guarantee that each entry will always have exactly one headword. So, when designing DMLex, we decided to favour computational simplicity, even if it means that formatting entries for human viewers is now a more complex process.
Our decision also means that the data model is simpler than it would be if we did allow multi-headwording: there are fewer object types and fewer properties in the model. We don’t need separate object types and properties for variant headwords, secondary headwords and such things: everything is just a headword (of its own entry). Also, one thing you sometimes see in multi-headword entries (in dictionaries that allow them) is that each co-headword almost has its own “mini-entry” describing its properties: labels like ‘American spelling’ as well as other stuff. This complicates the data model again because it becomes non-trivial to distinguish between information which applies to only one of the co-headwords and information which applies to the whole entry. In DMLex we decided to get rid of all those complications and we chose a brutally simplified way: each entry has exactly one headword, and if you need something more complicated you have to use relation objects for that.
Relations, relations everywhere
This is probably a lot to take in if all you’ve seen until now is XML-encoded dictionaries. We use these relation objects a lot in DMLex. We use them to represent things that are difficult to represent satisfactorily in a tree structure, such as cross-references: more about that later. But that’s not all. Additionally, we use relation objects for things that are representable in a tree structure but the representations would be computationally complex: like the headwords things we just went through.
I can understand that this fairly radical approach – relations everywhere! – might not resonate well with everybody in the lexicograhic industry. Different people may have different ideas about what is and what isn’t “complex”. Some people might feel that our solution is actually the more complex one. If you’re in that camp, then I’m afraid we will have to agree to disagree here. All I can tell you is that from the point of view of an IT person, working with data organised like this will be easier, even if it means that putting entries on screens requires additional processing.
So, what more can I tell you about these relation objects? One thing each relation object has is a property named type. You can define the relation types that exist in your dictionary and how your application is supposed to handle them (for example when showing entries to humans). Then, each relation object has at least two members or, more accurately, member objects. Each member object contains a reference (in its ref property) to something in your dictionary such as an entry or a sense, and optionally another property named role which specifies the role of this member in the relation. And you can define which roles exist for which relation types, of course.
This is the mechanics we have designed in DMLex for representing relations between entries and/or senses. We have just seen an example of how we’re using this mechanics to represent spelling variants of headwords. In the rest of this article you will see a lot more example of how DMLex uses relations for many other things, so do read on!
No more dangling cross-references
Let’s now look at a more classical use of relations: modelling cross-references from entries to other entries. In classical XML-based lexicography, a cross-reference is like a hyperlink on the web: it says “click here to go to this other entry”. The way a cross-reference is typically represented in XML has two problems. First, it doesn’t guarantee that the target of the cross-reference actually exists. Second, it doesn’t guarantee that the target contains a reciprocal cross-reference in the opposite direction (if reciprocity is expected).
In DMLex, we decided to solve this problem by redefining cross-references as relations. We aren’t actually modelling the cross-references, we are modelling the relations that motivate the cross-references. So, instead of saying “there is a link from entry A to entry B and there is another link from entry B to entry A”, we say “there is a relation between entries A and B”. The relation may or may not be shown to end-users as clickable cross-references, depending on the relation’s type and on how your application is programmed to handle it.
Let’s see an example. We have three entries for the headwords lens, glasses and microscope, with one sense each. We want to represent the fact that there is a meronymy (part-whole) relation between lens and glasses, and also between lens and microscope. We want these relations to be shown as cross-references at the end of the appropriate senses of the appropriate entries, like in Figure 3a.

The DMLex model of that is shown in Figure 3b. Notice that there are two relations of type meronymy: one between lens and glasses and another between lens and microscope. Each has two members pointing to the relevant senses, and each member has a role property to tell us which end of the relation it represents, the part or the whole.

In addition to all this, DMLex also gives you mechanics you can use to define that meronymy is one of the valid relation types in your dictionary, and that each relation of this type is supposed to have exactly two members, one with role part and one with role whole, each pointing a sense somewhere in the dictiionary. This is not shown in Figure 3b but trust me, it is possible to express these constraints in DMLex.
As you see, the entry for lens is a member in two relations. Both are listed as cross-references in the entry. An interesting question is, how does my application know which order to list them in? Is the listing order arbitrary, or can the lexicographer have control over it? The answer is that it is not arbitrary, the lexicographer is in control. The member objects have an optional property named listingOrder which controls the position of the member within the relation (like if you have a relation between three synonyms, you can control their order with this) and another property named obverseListingOrder which controls the position of this relation when listed under that member. OK, that probably sounds complicated at first, but take this from it: DMLex is an order-preserving data model. In DMLex, the lexicographer always has control over the listing order of everything, not just relations and their members, but also the senses inside entries, example sentences inside senses, and many other things. In fact, DMLex is able to express pretty much everything people are used to from classical XML-based lexicography, including listing order.
Subentries
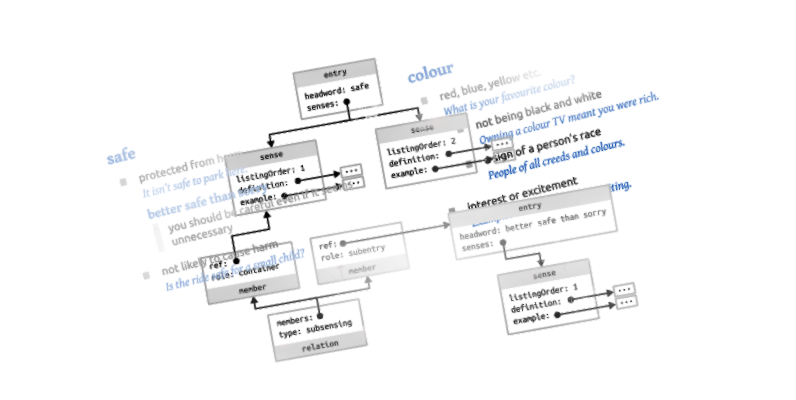
It is not unusual for dictionary entries to contain subentries. A “subentry” is a catch-all term I use for all kinds of things that aren’t top-level entries but do have something that looks like their own headwords. A subentry is like a mini-entry embedded inside a bigger entry. Their own local headwords are often multi-word items. An example can be seen in Figure 4a.

Notice how the entry for safe has two senses, the first of which contains a subentry headed by its own multi-word headword (or ‘title’ if you prefer) better safe than sorry. How would we represent this in DMLex? If you’re used to XML-based lexicography you would probably expect objects of type sense to be allowed to contain objects of type entry (or of some other but similar type such subentry), and this would create a recursive structure of entries inside entries. That’s not the DMLex way though. In DMLex we do not allow entries to be embedded inside entries, but we do allow relations to be created that say something like “please take this entry and embed it inside this other entry when showing it to a human end-user”. Figure 4b shows what that looks like when modelled in DMLex.

Notice that the entity that represents better safe than sorry is its own entry. There is a relation between it and the first sense of safe which says that the former is a subentry inside the latter. When your application is about to show the entry for safe to someone, it should be programmed to follow through on relations of this type, to grab the entry for better safe than sorry, and to temporarily insert it into its correct location inside he entry for safe, like in Figure 4a.
Once again you may be asking, why have we decided to do it this way in DMLex instead of allowing recursion (entries inside entries)? And once again I will tell you that the reason is avoidance of computational complexity. From the IT point of view, it makes things easier if we can guarantee that entries will always have a flat structure with no recursion. I have written a peer-reviewed paper where I argue why this is a good idea, you are welcome to read it and either agree or disagree. Alternatively, you can conclude than you don‘t care: the main thing for most lexicographers should be that yes, you can do subentries in DMLex, it’s just that the internal representation is different from what you may have seenm elsewhere.
There is one consequence, however, which might be of interest to lexicographers. Because of DMLex’s relations-based approach, you no longer have to decide whether a multiword subentry like black hole should be placed under black or hole. In DMLex, it can be under both! You simply create two relations, one between black hole and black, and another between black hole and hole.
Subsenses
Another thing which is quite common in dictionaries is senses inside senses. An example can be seen in Figure 5a: the entry for colour has two top-level senses the first of which has two subsenses.

The classical way to model such hierarchies is to allow objects of type sense to contain other objects of type sense (or of a diffent but similar type such as subsense), which once agains opens to door to our nemesis, recursion. But in DMLex we don’t like recursion (for reasons mentioned above) so, once again, we do it with relations instead. A DMLex entry always contains only a flat list of senses (we’re avoiding computational complexity by guaranteeing this), but you have the option to create relations between senses that give instructions to your application on how to re-arrange the sense into a hierarchy at display-time. Figure 5b shows what such a model looks like.

Separation of form and meaning
Once last thing I want to tell you about DMLex before this article concludes is that DMLex enforces a pretty strict separation between the formal properties of headwords (their orthography, morphology and phonology) and their semantic properties (their meaning and usage). The former is always recorded at the entry-level (as properties of the entry object) and the latter always at the sense-level (as properties of the sense object).
In dictionaries you sometimes see things like part-of-speech labels attached to individual senses rather than to the entire entry, or sense-specific inflected forms of the headword attached to indiviual senses. These things are prohibited in DMLex, for reasons which once again have to do with avoiding computational complexity. It makes things easier for IT tasks if we can guarantee that all the formal properties of the headword are at the entry-level and that no “surprises”, exceptions or overrides await further down inside the entry.
All of this does not mean that you can’t express sense-specific formal properties in DMLex. You can, but you have to do it differently. Let’s say you’re a lexicographer who wants to describe the headword walk which, as you know, is both a verb and a noun. One idea you may have is to create a single entry for this headword with one sense for the verb and another for the noun, like in Figure 6a.

You can’t do this in DMLex because it violates the principle of form/meaning separation. But you can use relations to approximate this at display-time for the human end-user. You need to create two separate entries for the two walks (you can think of this as effectively treating them as homonyms, or as “spreading” the headword over two entries), connect them with a relation, and program your application to handle this relation such that the on-screen display kind-of looks like a single entry. Figure 6b shows the model and Figure 6c shows what the end-user might see.


In conclusion...
Congratulations, you’ve reached the end of the article – which turned out to be quite a bit longer than I anticipated! Well, we did cover a lot of ground. DMLex is a large and complex beast, summarizing it in one handy read is a challenge. The reward is that you now have a profound understanding of how DMLex “ticks”. If what you have seen here intrigues you, then all that’s left for you to do is to go and read the whole thing.
As I said in the introduction, I am writing this at a time when DMLex has entered a second round of public reviews. What we hope to hear from people like you is two things. First of all, we want to know whether you agree or disagree with the design choices we have made for DMLex, epecially the whole relations thing. If you disagree, please give us your well-founded, rational arguments why. The second thing we want to hear is whether DMLex is able to represent all the things that you consider important in lexicography. DMLex doesn’t always represent things the way you expect – I’ve shown you how e.g. we avoid recursion – but it always has a way of representing things that are common in lexicography: subsenses, subentries, variant headwords and so on. If it seems like we missed something, then please tells us now before it’s too late.